Last week, I wrote about using automated detection and response technology to mitigate the next Corona pandemic.
Today – we’ll take a closer look at how streaming data fits into virtual clinical trials.
Streaming – not just for Netflix
Streaming real-time data and automated digital monitoring is not a foreign idea to people quarantined at home during the current COVID-19 pandemic. Streaming: We are at home and watching Netflix. Automated monitoring: We are now using digital surveillance tools based on mobile phone location data to locate and track people who came in contact with other CORONA-19 infected people.
Slow clinical trial data management. Sponsors flying blind.
Clinical trials use batch processing of data. Clinical trials currently do not stream patient / investigator signals in order to manage risk and ensure patient safety.
The latency of batch processing in clinical trials is something like 6-12 months if we measure the time from first patient in to the time a bio-statistician starts working on an interim analysis.
Risk-based monitoring for clinical trials uses batch processing to produce risk profiles of sites in order to prioritize another batch process – namely site visits and SDV (source data verification).
The latency of central CRO monitoring using RBM ranges wildly from 1 to 12 weeks. This is reasonable considering that the design objective of RBM is to prioritize a batch process of site monitoring that runs every 5-12 weeks.
In the meantime – the study is accumulating adverse events and dropping patients to non-compliance and the sponsor is flying blind.
Do you think 2003 vintage data formats will work in 2020 for Corona virus?
An interesting side-effect of batch processing for RBM is use of SDTM for processing data and preparing reports and analytics.
SDTM provides a standard for organizing and formatting data to streamline processes in collection, management, analysis and reporting. Implementing SDTM supports data aggregation and warehousing; fosters mining and reuse; facilitates sharing; helps perform due diligence and other important data review activities; and improves the regulatory review and approval process. SDTM is also used in non-clinical data (SEND), medical devices and pharmacogenomics/genetics studies.
SDTM is one of the required standards for data submission to FDA (U.S.) and PMDA (Japan).
It was never designed nor intended to be a real-time streaming data protocol for clinical data. It was first published in June 2003. Variable names are limited to 8 characters (a SAS 5 transport file format limitation).
For more information on SDTM, see the 2011 paper by Fred Woods describing the challenges to create SDTM datasets. One of the surprising challenges is data/time formats – which continue to stymie biostats people to this day. See Jenya’s excellent post on the importance of collecting accurate date-time data in clinical trials. We have open, vendor-neutral standards and JavaScript libraries to manipulate dates. It is a lot easier today than it was in June 2003.
COVID-19 – we need speed
In a post COVID-19 era, site monitoring visits are impossible and patients are at home. Now, demands for clinical trials are outgrowing the batch-processing paradigm. Investigators, nurses, coordinators and patients cannot wait for the data to be converted to SDTM, processed in a batch job and sent to a data manager. Life science sponsors need that data now and front-line teams with patients need an immediate response.
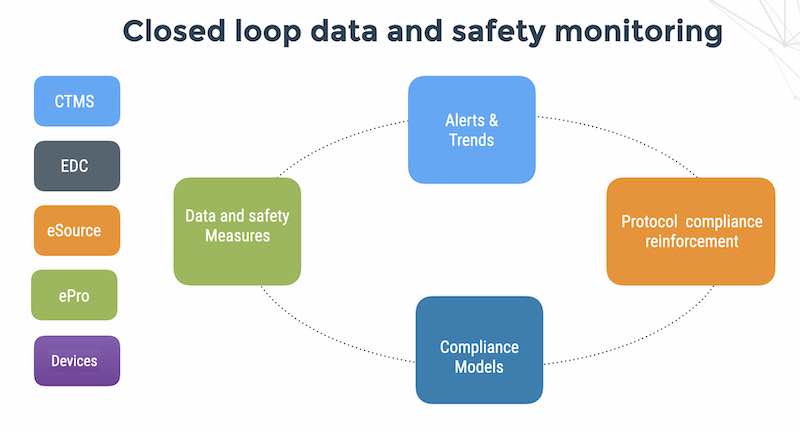
Because ePRO, EDC and wearable data collection are siloed (or waiting for batch file uploads using USB connection like Phillips Actiwatch or Motionwatch), the batch ETL tools cannot process the data. To place this in context; the patient has to come into the site, find parking, give the watch to a site coordinator, who needs to plug the device into USB connection, upload the data and then import the data to the EDC who then waits for an ETL job converting to SDTM and processing to an RBM system.
Streaming data for clinical research in a COVID-19 era
In order to understand the notion of streaming data for clinical research in a COVID-19 era, I drew inspiration and shamelessly borrowed the graphics from Bill Scotts excellent article on Apache Kafka – Why are you still doing batch processing? “ETL is dead”.
Crusty Biotech
The Crusty biotech company have developed an innovative oral treatment called Crusdesvir for Corona virus. They contract with a site, Crusty Kitchen to test safety and efficacy of Crusdesvir. Crusty Kitchen has one talented PI and an efficient site team that can process 50 patients/day.

The CEO of Crusty Biotech decides to add 1 more site, but his clinical operations process is built for 1 PI at a time who can perform the treatment procedure in a controlled way and comply with the Crusdesvir protocol. It’s hard to find a skilled PI and site team but the finally finds one and signs a contract with them.

Now they need to add 2 more PI’s and sites and then 4. With the demand to deliver a working COVID-19 treatment, Crusty Biotech needs to recruit more sites who are qualified to run the treatment. Each site needs to recruit (and retain more treatments).

The Crusty Biotech approach is an old-world batch workflow of tasks wrapped in a rigid environment. It is easy to create, it works for small batches but it is impossible to grow (or shrink) on demand. Scaling requires more sites, introduces more time into the process, more moving parts, more adverse events, less ability to monitor with site visits and the most crucial piece of all – lowers the reliability of the data, since each site is running its own slow-moving, manually-monitored process.
Castle Biotech
Castle Biotech is a competitor to Crusty Biotech – they also have an anti-viral treatment with great potential. They decided to plan for rapid ramp-up of their studies by using a manufacturing process approach with an automated belt delivering raw materials and work-in-process along a stream of work-stations. (This is how chips are manufactured btw).

Belt 1:Ingredients, delivers individual measurements of ingredients
Belt 1 is handled by Mixing-Baker, when the ingredients arrive, she knows how to mix the ingredients, then put mixture onto Belt 2.
Belt 2:Mixture, delivers the perfectly whisked mixture.
Belt 2 is handled by Pan-Pour-Baker, when the mixture arives, she can delicately measure and pour mixture into the pan, then put pan onto Belt 3.
Belt 3:Pan, delivers the pan with exact measurement of mixture.
Belt 3 is handled by Oven-Baker, when the pan arrives, she puts the pan in the oven and waits the specific amount of time until it’s done. When it is done, she puts the cooked item on the next belt.
Belt 4:Cooked Item, delivers the cooked item.
Belt 4 is handled by Decorator, when the cooked item arrives, she applies the frosting in an interesting and beautiful way. She then puts it on the next belt.
Belt 5:Decorated Cupcake, delivers a completely decorated cupcake.
We see that once the infrastructure is setup, we can easily add more bakers (PI’s in our clinical trial example) to handle more patients. It’s easy to add new cohorts, new designs by adding different types of ‘bakers’ to each belt.

How does cupcake-baking relate to clinical data management?
The Crusty Biotech approach is old-world batch/ETL – a workflow of tasks set in stone.
It’s easy to create. You can start with a paper CRF or start with a low-cost EDC. It works for small numbers of sites and patients and cohorts but it does not scale.
However, the process breaks down when you have to visit sites to monitor the data and do SDV because you have a paper CRF. Scaling the site process requires additional sites, more data managers, more study monitors/CRAs, more batch processing of data, and more round trips to the central monitoring team and data managers. More costs, more time and 12-18 months delay to deliver a working Corona virus treatment.
The Castle Biotech approach is like data streaming.
Using a tool like Apache Kafka, the belts are topics or a stream of similar data items, small applications (consumers) can listen on a topic (for example adverse events) and notify the site coordinator or study nurse in real-time. As the flow of patients in a study grows, we can add more adverse event consumers to do the automated work.
Castle Biotech is approaching the process of clinical research with a patient-centric streaming and digital management model, which allows them to expand the study and respond quickly to change (the next pandemic in Winter 2020?).
The moral of the story – Don’t Be Krusty.