Encouraging a participatory culture in clinical trials
Founder and CEO of flaskdata.io, Danny Lieberman wonders if the phenomenal success of the participatory code culture on GitHub can be copied to rejuvenate the clinical trial industry and break down barriers to entry and speed up product development.
Like a stranger in a strange land
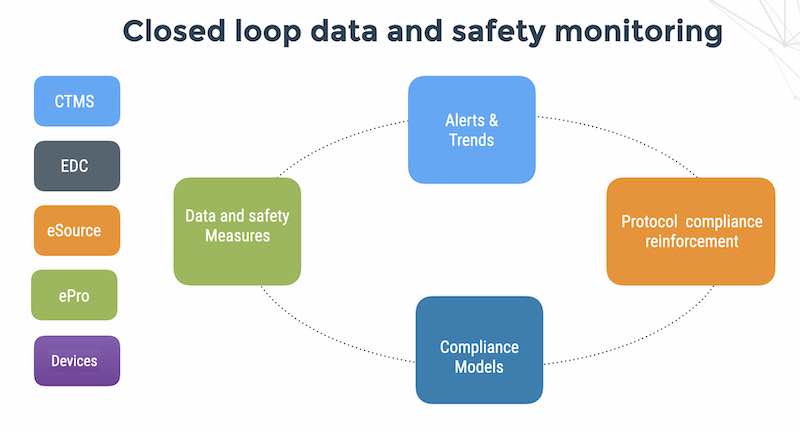
As a physicist and professional programmer, I feel like I am an outsider in clinical trials despite having started flaskdata.io 3 years ago and living to tell the story of how a small team with coding chops can deliver a system that automates monitoring of over 9M signals at 60 clinical trials at over 500 sites (flaskdata.io is a secure and privacy-compliant cloud-API platform for clinical trials)
There are 2 reasons why I feel like an outsider.
Reason # 1 is language.
With a graduate degree in physics and a career as a professional programmer, I am not a master of regulatory language despite having read FDA Guidance documents with impressive-sounding names like “Mobile Medical Applications, Guidance for Industry and FDA staff, “Post market Management of Cybersecurity in Medical Devices” and “Electronic Source Data in Clinical Investigations”.
Part of my language issue is a tension between regulatory agencies who tell you what you cannot do and entrepreneurs like me who want to do things.
I will illustrate this innovation-regulatory tension with two personal anecdotes.
I first shared my idea for “automated data and safety monitoring as a service” with the VP Regulatory Affairs of one of my medical device security consulting clients.
I spoke about our ideas for computing metrics (as opposed to harmonizing clinical data).
I then submitted that automating data and safety monitoring could be automated using real-time alerts on metrics over/under threshold (dosing compliance for example).
The data you collect in your EDC is far from big-data or high-velocity data like in cloud services.
Clinical data is tiny, tiny time-dependent, high-dimensional data. In Phase 3 vaccine trials — it is also highly cardinal data with 30–50,000 patients but still 3–4 orders of magnitude less than what Google or FB deal with monitoring systems.
You can create metrics and use alerts to identify problems (patients who failed IE criteria but participate in the study), investigate problems (discover who is involved, when it happened and what was done, if at all) and then escalate to human beings to resolve problems (having a playbook for instructing site investigators not to let it happen again and dropping the patients out of the study). Standard items like IE criteria and ICF (informed consent) are deterministic variables and when placed on an ordered timeline, it’s easy to see subjects downstream who are missing upstream criteria.
The VP Regulatory Affairs reacted in horror — “I don’t see how you can be allowed to do that without first validating it in a large number of test cases”.
I said — “well yes”. IF the monitoring software would be part of the quality system for medical device software itself, then it must be validated for the device intended use, as required by 21 CFR §820.70(i) but this is a productivity tool for the people monitoring and running the clinical trial of device safety and efficacy — not for the device itself.
She was very skeptical about automation and unfortunately, she remains a good friend and firm believer in 100% SDV to this day.
The second time was when I pitched to a regulatory affairs consultant.
I decided that this time I had to use the right language.
I framed my argument for automated clinical monitoring as a service as being aligned with the 2013 FDA Guidance for “Oversight of Clinical Investigations — A Risk-Based Approach to Monitoring”. Quoting chapter and verse from the 2013 FDA guidance document I told her that FDA believes that risk-based monitoring can improve sponsor oversight of clinical investigations and can meet statutory and regulatory requirements and that a review determined that centralized monitoring activities could have identified more than 90% of the findings identified during on-site monitoring visits. (Later we would discover that on-site monitoring visits and 100% SDV are incredibly useless activities affecting less than 1% of the clinical data collected.
In fact — automated monitoring of data and patient safety can identify 90% of the issues that the human study monitor should have identified but missed because they were counting beans and comparing pieces of paper with computer reports instead of looking for bodies and smoking guns).
I thought that if I spoke the language she would be impressed.
But alas no. The reaction was —
“Oh yes, I gave a talk about risk-based monitoring at a conference a couple of years ago. I know all about risk-based monitoring”. And would you be interested in seeing a demo? … Uh, I guess not.
This is a social situation is familiar to anyone who has learned a foreign language. You work hard, study grammar and go up to a woman in a bar in Rome and say in your best Italian “Ti ho visto qui prima?” and she says — “Oh no, I don’t speak English”. Breaks my heart every time. You don’t even get to try out “io ho una cotta per te” (Street Italian for I have a crush on you).

It’s depressing — like, heah man — I had a crush on Randi Barr-Gottlieb in Junior High and she let me carry her books for the year but she never noticed me.
You remember stuff like that.
The second reason is culture
Culture is more complex. Of course, culture is more complex since it involves language, people, values and rules.
The clinical trials industry culture is a fabric woven from a complex, highly political, ecosystem of pharma, medical device vendors, regulatory bodies, CROs, suppliers, consultants, hospitals, physicians, service providers and technology companies.
Clinical trials online media is clearly dominated by American big pharma with deep pockets for clinical trials and even deeper pockets for marketing. As a result, IT suppliers’ price and package their products as eClinical platforms for high-end, big-budget enterprise customers and bundle their offerings with profitable consulting services for the implementation. Along with the platform orientation comes regulatory requirements for electronic submission to FDA (21 CFR Part 11 Guidance for Electronic Records; Electronic Signatures — Scope and Application) and more recently, regulatory requirements to use CDISC Standards for regulatory submissions to FDA in the US and PMDA in Japan.
CDISC is an example of a large enterprise mindset that erects complex and costly technology barriers to adoption. On one hand, the CDISC mission on the Web site is “Unlocking cures is our life’s work. At CDISC, we enable clinical research to work smarter by allowing data to speak the same language.” Benefits of implementing CDISC standards include (quoting from the web site) better quality and lower costs and streamlined processes).
Yet, the CDISC SHARE API is only available to licensed users who pay a fee of $12,000/year for Platinum CDISC members who pay $4,000/year for membership. So, for $16K/year — you can use a Restful API to “programmatically retrieve CDISC standards’ metadata from SHARE to support process automation”. (APIs from Facebook, Google and Yahoo and thousands of other Internet companies are free, open-source and available on GitHub).
Another case of barriers to adoption is CDISC BRIDG: “BRIDG is a domain analysis model that represents the realm of protocol-driven clinical, pre-clinical, translational and basic research”. BRIDG seems to have a vision of computable clinical protocols ensuring a valid experimental model before starting a trial but unfortunately, I still do not understand what BRIDG is trying to achieve after spending several hours reading online documentation. My ability to take a closer look was hobbled by the fact that you need a closed-source Enterprise modeler application which only runs on Windows. (If you use OS/X and Linux you are apparently not welcome to the CDISC/BRIDG program).

An interesting side-effect of the big-enterprise/big-pharma Weltanschauung is that the small low-cost cloud EDC vendors who charge $200/month for cloud data management use big-pharma marketing buzz-words. To me it is incongruous, like mothers and their small daughters wearing the same clothes. If you are a small software vendor in any other space, you would need to innovate and have a unique value proposition in order to survive instead of positioning yourself as a little girl wearing a tiny edition of her mother’s evening gown.
My first thought on all of this was, OK — I get it. It’s just enterprise software and management consulting with a lot of regulation thrown in.
But not really.
The clinical trials industry is the last bastion of big money industries using vintage 80s people and process. The accounting industry stopped using manual data entry from paper journals back in the 80s. Transaction processing processes in manufacturing, financial services, global supply-chain and trading went through numerous business-process-reengineering changes over the past 30 years, unlike the clinical trials industry which is stuck in vintage 80s paper and people-intensive processes. With 20,000 new clinical trials every year, VC funding, and strong regulation, perhaps there is not enough incentive to reengineer process like there was in the retail and manufacturing industries during the 80s and 90s of the previous centuries.
Let’s compare the clinical trials industry to software development on Github (see https://github.com/about. GitHub is a collaborative a community where more than 21 million people learn, share, and work together to build software. With only 600 employees worldwide, Github hosts over 57 million projects. The API’s on GitHub are free and open to anyone to fork (create his or her own version). If you can program and search, all you need is GitHub, Google and Stackoverflow.
GitHub is not just for software coders. There are people using GitHub to compose music, to share recipes, and even for legal documents. For example, Stefan Wehrmeyer, a German software developer and freedom of information activist has posted the German federal government’s laws and regulations to GitHub. Allowing anyone to track changes, see who made the changes, and why. Thus, not only providing traceability of the changes, but with the use of GitHub’s diff functionality showing what exactly has been changed.
But consider this — Git was created by Linus Torvalds in 2005 for development of the Linux kernel, with other kernel developers contributing to its initial development. Its current maintainer since 2005 is Junio Hamano.
One person who write the core software. 600 people to develop and maintain the online services for collaboration and a participatory culture for over 57 million projects and 21 million people.
Compare that to FDA with 15,000 employees and 50,000 submissions/year according to the FDA 2015 Annual report. That is a ratio of 3 projects per employee unlike Github that has a ratio of 100,000 projects per employee.
Looking at the GitHub case, it would seem that an online participatory model has the potential to be as much as 6 orders of magnitude more effective than the current model of clinical trials.
CDISC wants to make it easier to submit clinical trial data for regulatory review whereas GitHub helps entrepreneurs and innovators get great products out to market faster.
There are some very complex clinical trials — but there are also some very complex and big software projects on GitHub — including the Linux kernel itself and TensorFlow — an automated system for speech recognition.
I believe that the participatory and collaborative model of GitHub surely must have relevance to the world of clinical research. If not for FDA submissions, then for sharing problems and solutions, creating tools and collective learning without disclosing valuable intellectual property.
GitHub itself can be a community of practice for the clinical trial community.
See http://juretriglav.si/3-simple-things-github-can-do-for-science/ and https://github.com/search?utf8=%E2%9C%93&q=clinical&type= to see over 1800 repositories on GitHub working on clinical software development.
Communities of practice are formed by people who engage in a process of collective learning in a shared domain of human endeavor: a tribe learning to survive, a band of artists seeking new forms of expression, a group of engineers working on similar problems, a clique of pupils defining their identity in the school, a network of surgeons exploring novel techniques, or a gathering of new clinical trial monitors helping each other.
http://wenger-trayner.com/introduction-to-communities-of-practice/
I do not pretend to know how to make this happen — but if I were an activist intent on revolutionizing healthcare economics, I would start by revolutionizing clinical trial economics via technology and business models from the DevOps world. But that is a story for another essay.
This post was originally posted on Medium – Can one Web site change healthcare economics?
Danny Lieberman is the Founder and CEO of Flaskdata.io – an Israeli tech startup that understand that you need to stop guessing about your clinical data.